
All Posts
Are File Systems All You Need? It Depends...
By Joachim Rahmfeld
TL;DR
File systems have recently become very popular and much discussed in the context of Agentic AI. As ‘finding stuff’ is a core component of most agentic flows, we were very interested in specifically comparing the effects of hybrid search (keyword + semantic search, backed by a vector database) and file search (glob/grep/read) as the retrieval backbones for agentic AI workflows. Using Onyx's agentic chat loop (hybrid search) and Onyx Craft (file search, in beta), we tested on a synthetic enterprise dataset at two scales: ~160k and ~510k documents, without significant tuning beyond making the approaches similar. We used Cohere embed-english-v3.0 for embeddings and OpenAI GPT-5.4 as the LLM.
We found:
- Narrow, single-document questions: Hybrid search outperformed file search in document recall (92% vs 85%) and was ~4× faster (21s vs 87s).
- Complex, multi-document questions: File search pulled ahead - 76% document recall vs 57% for hybrid search - by leveraging its ability to gather broad context across many files. Run times were still higher (~160s vs ~53s).
- Scaling to ~510k documents: Hybrid search held steady, while file search recall dropped substantially (24 percentage points averaged over all question categories). The core issue: the agent narrows its grep patterns to manage larger result sets, inadvertently missing relevant documents.
- Speed & cost: Hybrid search is significantly faster and more token-efficient across the board.
The takeaway: neither approach dominates everywhere… We believe future optimized systems will combine both to optimally address the user need in a given situation.
1. Introduction
Recently, there has been a lot of discussion about using file systems versus vector embeddings as the underlying framework for search- and knowledge-acquisition components of agentic workflows. Examples of tools that use file search as the core of their retrieval mechanism include Claude Cowork, Onyx Craft (in beta), and OpenClaw.
File (system) search - built largely on glob, grep, and read - in a way mimics how humans actually work through a corpus of documents. For example, if you had to find what price was quoted to a prospect as part of a sales opportunity, you would likely look through files with the customer name in the title, search for lines containing "price" alongside the customer name, inspect the results, and then decide to read a few promising documents before either searching further or extracting the answer. File search takes exactly this approach: depending on the query, glob analyzes the directory structure to surface promising file candidates, grep finds patterns in files and returns matching lines, and read allows reading of full or partial candidate documents.
This approach is decidedly different from that of hybrid search. Hybrid search combines a keyword and a semantic search component to retrieve matching results from a vector database. First, all data is split into text chunks, which are then vectorized (capturing the semantic meaning of the chunk) and indexed. The keyword component attempts to match chunks typically using the classic BM25 algorithm or a modification of it. BM25 refines the basic TF-IDF, which scores a chunk for a given query based on how often the query terms appear in it, weighted by how rare those terms are across the corpus. The semantic component vectorizes the query and ranks chunks based on their vector similarity to the query vector. A final ranking then combines the results from both components.
Given the new developments, it is worthwhile to compare the file and hybrid search in terms of their effectiveness. Which one is better, under which conditions? And how does scale affect the answer?
We should note that we were analyzing here mainly the base behavior and patterns, as both approaches have substantial tuning, customization, and extension opportunities which would likely have a noticeable impact on the results.
2. Result Characteristics of Both Search Approaches
The file/directory search approach and the standard keyword/semantic (hybrid) search approach differ in three important ways regarding their impact on the agent loop and the answer quality, as discussed below.
Search Hits
Here is, at a high level, how hybrid search and file search differ:
| Hybrid Search | File Search | |
|---|---|---|
| Keyword-centric matching | BM25-style scoring: important/rare words weighted more heavily | Exact phrase match (with wildcards); all words in the clause matter equally - the agent must decide which are key |
| Semantic matching | Vector embeddings natively capture meaning; a single query can surface paraphrased or conceptually related content | Must be emulated through multiple rewordings; becomes increasingly hard as the "effective context" of the query grows, since the number of realistic phrasings grows roughly exponentially with length |
| Metadata filtering | Supported but often secondary | Natural strength - file names, directory structure, and metadata are first-class citizens |
Table 1: Hybrid search vs file search characteristics
Ranking
Hybrid search returns a ranked list of text chunks, each scored by relevance. File search on the other hand has no intrinsic ranking: a line either matches a grep pattern or it doesn't. The result set can be any size, which gives the agent flexibility but also responsibility: it must decide whether to narrow or broaden the search, depending on how many results were retrieved.
Completeness
This is perhaps an underappreciated distinction. Hybrid search returns the top-k chunks, but there is no inherent signal for how many of those are actually relevant, or how many relevant chunks were missed after the cutoff. File search, by contrast, returns all matches for a given pattern. The agent knows exactly how many documents matched - the set may be large or small, the search argument may or may not be ideal, but there is at least a clear sense of completeness with respect to the searches the agent chose to run.
3. What We'd Expect
Before looking at results, it's useful to lay out predictions based on the properties above. This gives us a framework for interpreting the data.
Hybrid Search Predictions
Basic, narrow questions should be its sweet spot - good keyword overlap and strong semantic match.
Complex multi-document questions should be harder, since complex analyses must be stitched together from multiple individually narrow searches, each returning a limited window of k chunks.
Scaling should be relatively benign. Doubling the corpus roughly doubles the rank position of a given target chunk. (And in fact this is a conservative estimate as often the new documents may be more relevant.) As long as the target document remains within the top-k cutoff, recall is unaffected.
File Search Predictions
Complex multi-document questions should be a relative strength, because the agent receives a broad set of matching lines across many documents and can reason holistically instead of being presented with a narrow top-k list.
On the other hand, basic questions may actually be harder as file search lacks the keyword-importance weighting and semantic similarity that make narrow lookups efficient.
Scaling is where we may expect real trouble. A common pattern looks like this: The agent generates initial grep arguments and retrieves matches. At larger corpus sizes, the result set may be too large to manage. The agent may then narrow the search by either using longer, more specific match strings, and/or by restricting the search to a more narrow area in the directory structure.
Because the number of realistic phrasings grows exponentially with sequence length, the narrower search may then often miss relevant documents - while still returning enough plausible content for the agent not to notice its ‘mistake’. Restricting the search to a sub-part of the directory structure has similar challenges.
Let's see if the data bears this out.
4. Setup & Evaluation
Dataset
We use our internal IndustrialRAG (IRAG) dataset, which we intend to fully open-source in the near future. It is designed to mimic typical enterprise content: Google Docs, Slack messages, call transcripts, engineering tickets, emails, CRM data, etc.
To observe scaling behavior, we evaluate on both the Full Set (~510k documents) and a Restricted Set (~160k documents):
| Document Type | Full IRAG Set | Restricted IRAG Set |
|---|---|---|
| Confluence articles | ~5k | ~5k |
| Fireflies call transcripts | ~10k | ~10k |
| GitHub PRs | ~8k | ~8k |
| Google Drive documents | ~25k | ~18k |
| Gmail messages | ~126k | ~115k |
| HubSpot accounts | ~15k | ~5k |
| Slack messages | ~285k | ~1k |
| Linear tickets | ~35k | ~800 |
| Jira tickets | ~6k | ~300 |
| overall # of documents | ~510k | ~160k |
Table 2: Decomposition of the synthetic dataset
How hard and representative is this dataset?
The difficulty of retrieval depends to a good extent on how similar the documents are to each other. 100k documents on unrelated topics may be far easier to search than 20k documents on a very narrow set of subjects. To characterize this, we determine:
- Average in-source cosine similarity (a measure of how ‘localized‘ each source's embeddings are): 0.453
- Average cross-source cosine similarity (a measure of how ‘well-separated’ different sources are): 0.408
- Average cosine similarity of Top-10 nearest neighbors (a measure of how ‘dense’ the dataset is): 0.876
The consistent pattern, intra-source similarity exceeding cross-source similarity for nearly every source, is statistically significant (analogous to an ANOVA F-test across source groups), but the gap is small.
Compared to our own internal Onyx company data:
- Cross-source separation is substantially larger in our real data.
- Within-source similarity is higher in IRAG.
- Top-10 nearest-neighbor similarity is higher in IRAG.
In addition, the IRAG dataset does not come with a lot of metadata that in a realistic indexing scenario may be extracted.
Overall, this suggests the IRAG dataset is actually denser and harder than typical enterprise data with the same number of documents. File search results in production may therefore be somewhat better than what we report here; hybrid search results may also improve. We plan to expand on this characterization (including distributional statistics) in future work.
Questions
All questions are generated from the Restricted Set (which is a subset of the Full Set). We consider three types:
| Type | Number | Description | Example |
|---|---|---|---|
| Single-doc: basic questions | 20 | Straightforward factual questions answerable from one document | "Who is responsible for updating the sample documents so the example corpus is clearly synthetic and has no personal or customer-like content?" |
| Single-doc: semantic questions | 15 | Questions related to a document's content but phrased more abstractly | "How much time off does the company offer for new parents in 2025 for the main parent versus the other parent, and when does that change take effect?" |
| Multi-doc: complex questions | 16 | Questions requiring synthesis across multiple related documents | "A dedicated customer reports request log retention is not being enforced in us-east; what is our triage and mitigation plan, and what evidence artifacts should we include in the compliance pack response?" |
Table 3: Makeup of test questions
We intend to share the full set of questions along with the upcoming open sourcing of our synthetic IRAG dataset.
Metrics
| Metric | Description |
|---|---|
| Document Recall | Average ratio of gold documents cited in the response of the agent |
| Time-to-Last-Token | Total agent run time in seconds, which includes query generations, thinking and complete answer composition |
Table 4: Metrics
For the purpose of this exercise, we decided not to score the quality of the answer or the retrieved facts itself as those tend to be a bit more susceptible to the details of the agent specification.
Search Approaches & Models
| Hybrid Search (Onyx Chat Loop) | File Search (Onyx Craft) | |
|---|---|---|
| Retrieval Structure | Query expansion into sub-queries → hybrid search per sub-query → relevance classification of chunks → optional full-document read → additional search rounds as needed | Agentic loop (via OpenCode) using glob, grep, and read over the document file system |
| Embeddings | Cohere 3.0 (embed-english-v3.0) | N/A |
| LLM | OpenAI GPT-5.4 | OpenAI GPT-5.4 |
Table 5: Base models
We adjusted prompts for both loops to target similar answer requirements and removed Craft's ability to generate dashboards, images, and similar outputs. By design, we did not add skills or complex context-management strategies to Craft, as we are interested in evaluating the baseline search behavior.
Limitations
A few caveats to keep in mind:
- The specifics of Onyx Craft and the standard Onyx chat loop differ in ways beyond the search mechanism, so results should be interpreted as directional.
- We did not substantially tune prompts or loop details. These are baseline results; both approaches could be improved with additional effort. (See suggestions later.)
- We did not systematically verify that no non-gold document in the corpus is actually more relevant than the gold document. However, in nearly all manual spot-checks, when the gold document was shown to the system after it had missed it, the system judged the gold document to be more suitable than the one it retrieved.
- A retrieved document that isn't the gold document may still be quite relevant and useful. Our metrics treat it however as irrelevant, a conservative simplification that may however overpenalize.
- Similarly, given the synthetic nature of the corpus, similar facts may appear in multiple documents, meaning the agent can sometimes find correct information without locating the ideal source.
- The number of questions, 51, is not very high, limiting statistical significance. We improved this to some extent by running the hybrid search loop multiple times, obtaining - for this question set - standard deviations of 0.03 for document recalls.
Overall, we view this as an exercise providing useful observations and a deeper understanding of essential patterns, rather than a rigorous benchmark.
5. Results
Main Results
| Dataset | Type | Document Recall | Time-to-Last-Token (s) |
|---|---|---|---|
| Hybrid / File | Hybrid / File | ||
| Restricted Set (160k docs) | single-doc: basic (n=20) | 92% / 85% | 21 / 87 |
| single-doc: semantic (n=15) | 87% / 87% | 32 / 110 | |
| multi-doc: complex (n=16) | 57% / 76% | 53 / 160 | |
| Full Set (510k docs) | single-doc: basic (n=20) | 92% / 70% | n/a / 210 |
| single-doc: semantic (n=15) | 82% / 53% | n/a / 214 | |
| multi-doc: complex (n=16) | 61% / 54% | n/a / 219 |
Table 6: Document Recall and Time-to-Last-Token for hybrid search- and file search-based loops
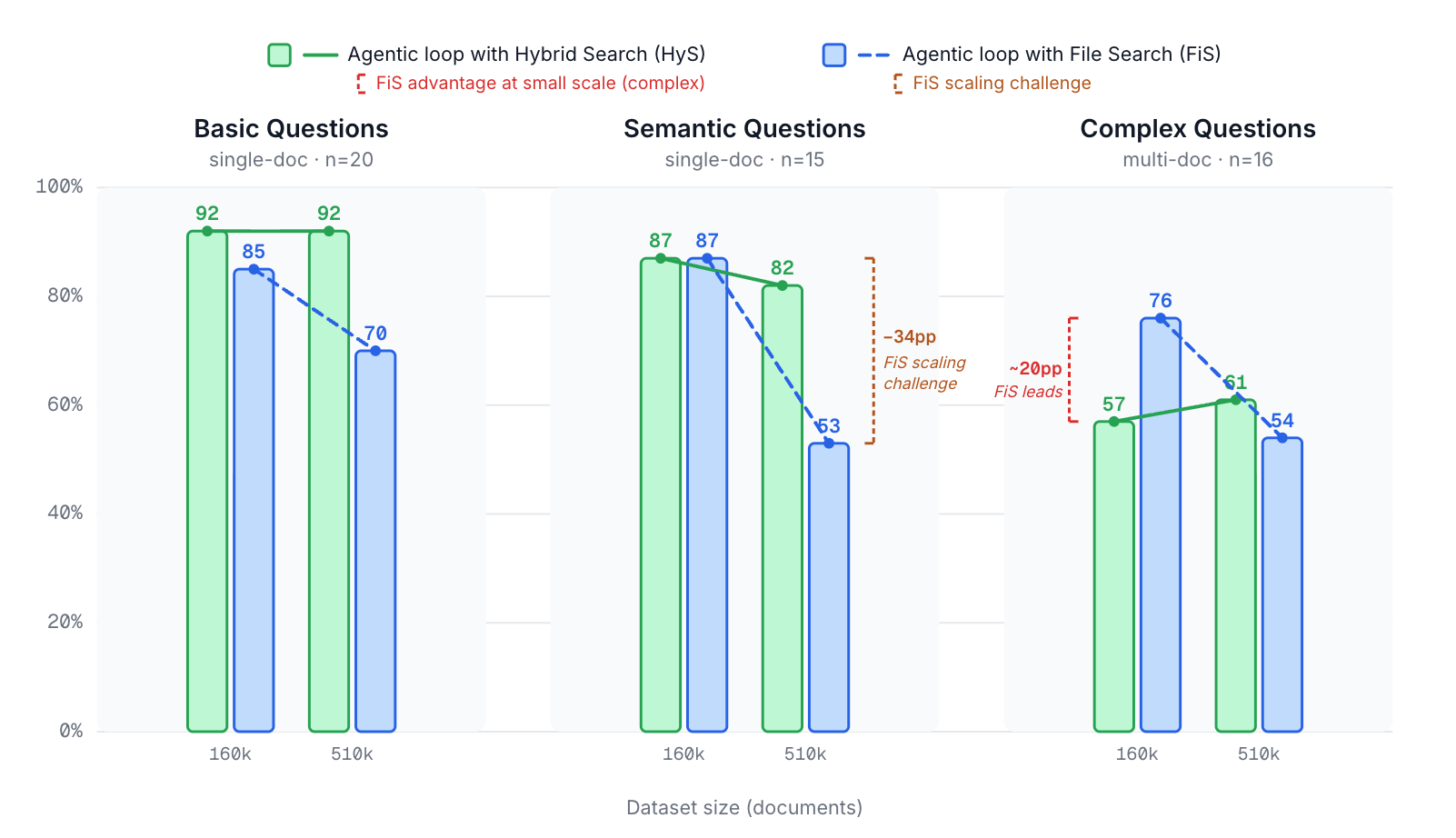
Image 1: Document Recall averages by question type and dataset size of synthetic dataset
Some notable side comments:
-
We ran various experiments multiple times, and we estimate - for our set of questions - the margin of error to be about 2-4 percentage points. Overall, we believe the patterns to be robust, except likely for the Document Recall increase from Restricted to Full Set for hybrid search of complex questions.
-
The hybrid search tests for the Full Set were conducted on a different server. We therefore do not report on the exact average durations. However, they were, as expected, of the same order as the corresponding results for the Restricted Set.
-
As the average cost to answer a query depends substantially on the LLM used, we do not explicitly report it. However, consistent with the substantially longer run times, file search was significantly more expensive per query in our tests.
Do the Predictions Hold?
Quite closely. Let's check them off:
Hybrid search:
-
Best on basic single-doc questions (92% document recall at both scales).
-
Harder on complex multi-doc questions (57% at 160k).
-
Robust to scaling — recall essentially unchanged between 160k and 510k.
File search:
-
Strongest on complex multi-doc questions at manageable scale (76% vs. hybrid's 57% at 160k).
-
Weaker on basic narrow questions (85% vs. hybrid's 92% at 160k).
-
Significant degradation at scale:
-
basic: 85% → 70%
-
semantic: 87% → 53%
-
complex: 76% → 54%
-
-
Substantially slower (and more token-intensive) across the board.
The scaling degradation follows the predicted pattern: at 510k documents, we observed the agent narrowing grep patterns to manage result-set size, then missing relevant documents that didn't match the more restrictive patterns.
Here is one explicit example that illustrates the scaling behavior of the file search approach:
Question:
“In the Redwood partnership discovery call with a cloud GPU systems integrator, what was the typical provisioning timeline mentioned for a private VPC deployment in the EU region?”
Outcomes:
| 160k (Restricted Set) | 510k (Full Set) | |
|---|---|---|
| Search Behavior | → various globs and greps → no concerns result set being too large → more greps and a read of the correct target document → proper answer provided with target document cited | → various globs and greps → result set reported to be too large → narrowing down aggressively to sub-directories → reading and answering with various documents that are relevant but not the target ones |
| Outcome | ✅ Found key document | ❌ Missed key document |
| Agent self-diagnosis | — | "I missed it because I narrowed the search too aggressively to knowledge_data/fireflies/partners/ and related partner folders after seeing many partnership-style transcripts there…" |
Table 7: Question and response patterns
A Note on Completeness
We did not explicitly test questions that depend on retrieval completeness (counting, aggregation, exhaustive enumeration). By design, hybrid search does not perform well on these as there is no signal for "you've found everything." We expect, and see in many anecdotal examples, that file search does substantially better here. A systematic evaluation is left for future work.
An Important Caveat on "Misses"
When file search misses the gold document, it does not return empty-handed. Particularly for complex multi-document questions, the file search often retrieves related documents containing similar facts. The information may not come from the ideal source, but it is frequently relevant and useful. Our strict metric (gold document or nothing) understates this.
6. Potential Improvements
Both approaches can be improved, and we plan to revisit this dataset to test some of these ideas.
For File Search
| Improvement | Rationale |
|---|---|
| Scratchpad / intermediate file writes for managing large context (cf. LangGraph Deep Agents) | Addresses the core scaling problem — the agent could retain and organize broad search results instead of narrowing prematurely |
| Source-specific AGENTS.md files and skills per directory | Better tailors search behavior to document type (e.g., Slack vs. Confluence) |
| Lightweight keyword index built at ingestion time | Acts as a semantic pre-filter, bridging the gap between raw grep and semantic search |
| General AGENTS.md optimization | Our vanilla configuration leaves room for a more sophisticated agentic flow |
Table 8: Some optimization options for file search-based agentic loops
For Hybrid Search
| Improvement | Rationale |
|---|---|
| Increase control by Agent Loop over details of the search process | Can for example allow the agent to paginate searches (‘now give me chunks k to 2k’), dynamically adjust hyper-parameters, etc. |
| Virtual file system overlay on top of the vector store to be able to use also file system tools, as recently pioneered by mintlify | Enables more targeted sub-searches, improving recall on complex queries |
| Document deduplication tracking across search rounds | Avoids wasting context when the same document surfaces in multiple sub-queries |
Table 9: Some optimization options for hybrid search-based agentic loops
For both approaches, the choice of LLM matters. Further analysis using Anthropic's Claude and open-source models is planned.
7. Conclusion
The picture is nuanced but clear in its broad strokes:
| Scenario | Winner |
|---|---|
| Narrow, single-document questions | Hybrid search — faster, cheaper, better recall |
| Complex, multi-document questions (moderate scale) | File search — broader context, higher document recall |
| Large-scale corpora | Hybrid search — robust where file search degrades without additional scaffolding |
| Completeness-dependent questions (counting, aggregation) | File search (expected and in practice observed, not yet systematically tested) |
| Speed & cost efficiency | Hybrid search — significantly faster and more token-efficient |
Table 10: Comparison of approaches
File search's strengths - holistic context, completeness awareness, natural metadata filtering - complement hybrid search's strengths - speed, semantic understanding, scale robustness. The approaches are not competitors so much as future collaborators.
We believe that optimized knowledge-acquisition systems will combine both techniques: using hybrid search for fast, targeted retrieval and file search for deeper, more exhaustive exploration when the question demands it.
Exciting times ahead!
Related Posts
On The Intrinsic Knowledge Retrieval Scaling Challenge
We study how, and in what way, scaling of a corpus affects basic retrieval recall (semantic search and BM25 search)
Benchmarking agentic RAG on workplace questions
Onyx outperformed ChatGPT Enterprise, Claude Enterprise, and Notion AI in an RAG benchmark using our internal and web data, complementing our recent Deep Research benchmark success.
Lessons from building the best Deep Research (and how you can build better agents)
A practical, behind-the-scenes look at how we built the #1 Deep Research system and the design choices that create performant agent systems.